MIDI Dual-Transformer
A transformer architecture for event-based MIDI generation.April 28th, 2025A Project Combining Music and Code
This project stemmed from my interest in both music production and machine learning. As someone who's been involved with music for pretty much my whole life, I've always been drawn to the intersection of technology and creative expression like in music production or in this case - AI. Working with machine learning models for MIDI generation seemed like a natural exploration, given that MIDI forms the backbone of most digital music production. Every digital audio workstation (DAW) such as FL Studie, Ableton or Logic Pro relies on MIDI for composition and arrangement, making it an interesting format to work with from a technical perspective.
MIDI in Modern Music Production
For those unfamiliar, MIDI (Musical Instrument Digital Interface) is a protocol that represents musical information as discrete events rather than audio data. It encodes which notes to play, their timing, duration, and velocity - essentially all the information needed to recreate a performance without the actual sound. The structured nature of MIDI makes it particularly suitable for machine learning applications. While there's been significant progress in raw audio generation, MIDI provides a more manageable representation for exploring architectural decisions in music generation models, which is why it's also referred to as "symbolic music generation".
Comparing Architectural Approaches
In this project, I implemented two different transformer-based architectures from scratch for MIDI generation:
- A basic transformer with a simple tokenization approach
- A more complex dual event transformer with hierarchical processing by SkyTnT
My goal was to document how these architectural differences affect the musical output, training efficiency, and practical usability of the generated content. The results revealed trade-offs between model complexity, training requirements, and the musical quality of the output - particularly regarding rhythmic precision and structural coherence. In this post, I'll walk through the technical implementation, share examples of the generated output, and discuss the practical implications for MIDI generation in music production contexts.
The Music Generation Challenge
Generating music programmatically presents several challenges that differentiate it from text generation. While both involve sequential data, music contains complex hierarchical structures and multi-dimensional information that must maintain coherence across multiple timescales simultaneously.
Beyond Linear Sequences
Text generation primarily deals with one-dimensional sequences where each token influences nearby tokens. Music, however, incorporates multiple parallel dimensions that must remain coherent both horizontally (across time) and vertically (across simultaneous notes):
- Rhythm: Precise timing relationships between notes, with patterns operating at multiple levels from microsecond articulations to bar-level phrases
- Harmony: Multiple notes sounding simultaneously that must follow musical theory constraints
- Melody: Horizontal sequences of notes that create recognizable themes
- Structure: Larger organizational patterns like verses, choruses, and repeated sections
Hierarchical Organization
Music naturally organizes into nested hierarchical levels:
- Micro level: Individual note properties (pitch, duration, velocity)
- Phrase level: Short musical ideas spanning several notes
- Section level: Verses, choruses, bridges forming complete musical thoughts
- Composition level: Overall structure and thematic development
A model must somehow capture these relationships across many different time scales. For example, a motif introduced in the first eight bars might need to be referenced or developed hundreds of tokens later.
Technical Implications
These musical properties directly influence architectural decisions in model design:
- The need for relative positional awareness so patterns can be recognized regardless of where they appear
- Mechanisms to handle long-range dependencies between distant elements
- The ability to process both local details (individual notes) and global structure (overall form)
These considerations led me to explore two different architectural approaches: a simple transformer focusing on sequential note events, and a hierarchical model that attempts to explicitly capture different levels of musical structure.
Breaking Down the Two Approaches
In exploring MIDI generation, I implemented two distinct architectural approaches, each with its own tokenization strategy and sequence modeling approach. The differences between these models highlight important trade-offs in complexity, efficiency, and musical quality.
Simple Approach: Base Transformer
The first approach employs a minimalist tokenization strategy with a standard transformer architecture, focusing exclusively on essential note events.
Tokenization and Architecture
The Base Transformer uses a streamlined tokenization process that reduces MIDI to three core elements:
- Time differences between notes (tokens 0-127)
- Note durations (tokens 128-255)
- Pitch values (tokens 256-833)
This creates a flattened, one-dimensional sequence where each MIDI file becomes a simple stream of tokens following this pattern:
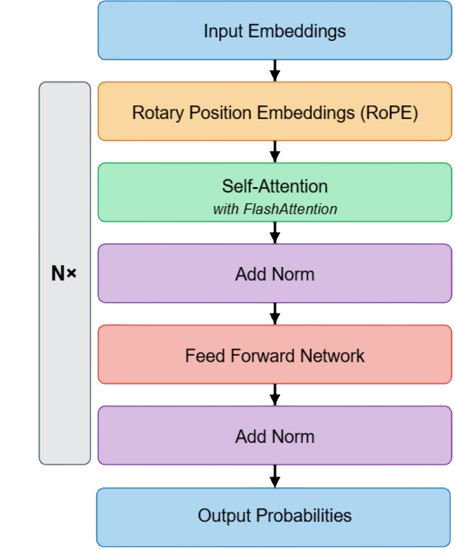
The model architecture is a standard decoder-only transformer that incorporates two modern improvements:
- Rotary Position Embeddings (RoPE) to capture relative positions
- FlashAttention for improved computational efficiency
Computational Efficiency
This approach offers several practical advantages:
-
Fast Training: With a simplified vocabulary of ~835 tokens and minimal architectural complexity, the model converges quickly even on limited data.
-
Low Resource Requirements: The model trained successfully on consumer-grade hardware (single GTX 3070Ti GPU), with each epoch completing in minutes rather than hours.
-
Data Efficiency: The model demonstrated the ability to learn meaningful patterns from just 570 MIDI files, making it suitable for genre-specific generation with limited datasets.
Limitations
The primary limitation of this approach became evident in the generated output:
-
Rhythmic Imprecision: The model often produced timing inconsistencies, with notes falling slightly off-beat in ways that would be problematic in a professional production context.
-
Limited Musical Context: By discarding higher-level musical information like time signatures, key signatures, and tempo changes, the model lacks awareness of broader musical structures.
-
Simplified Expression: The basic tokenization scheme doesn't capture expressive elements like dynamics changes, control signals, or program changes that add depth to a musical performance.
This approach captures melodic patterns effectively but struggles with the precise rhythmic alignment essential for practical use in music production environments.
Complex Approach: Dual Event Transformer
The second approach implements a hierarchical model with a much richer tokenization strategy to address the limitations of the simpler model.
Hierarchical Architecture
The Dual Event Transformer consists of two cooperating transformer networks:
- An event-level transformer that models high-level musical context and relationships between complete musical events
- A token-level transformer that handles the specific details of each event
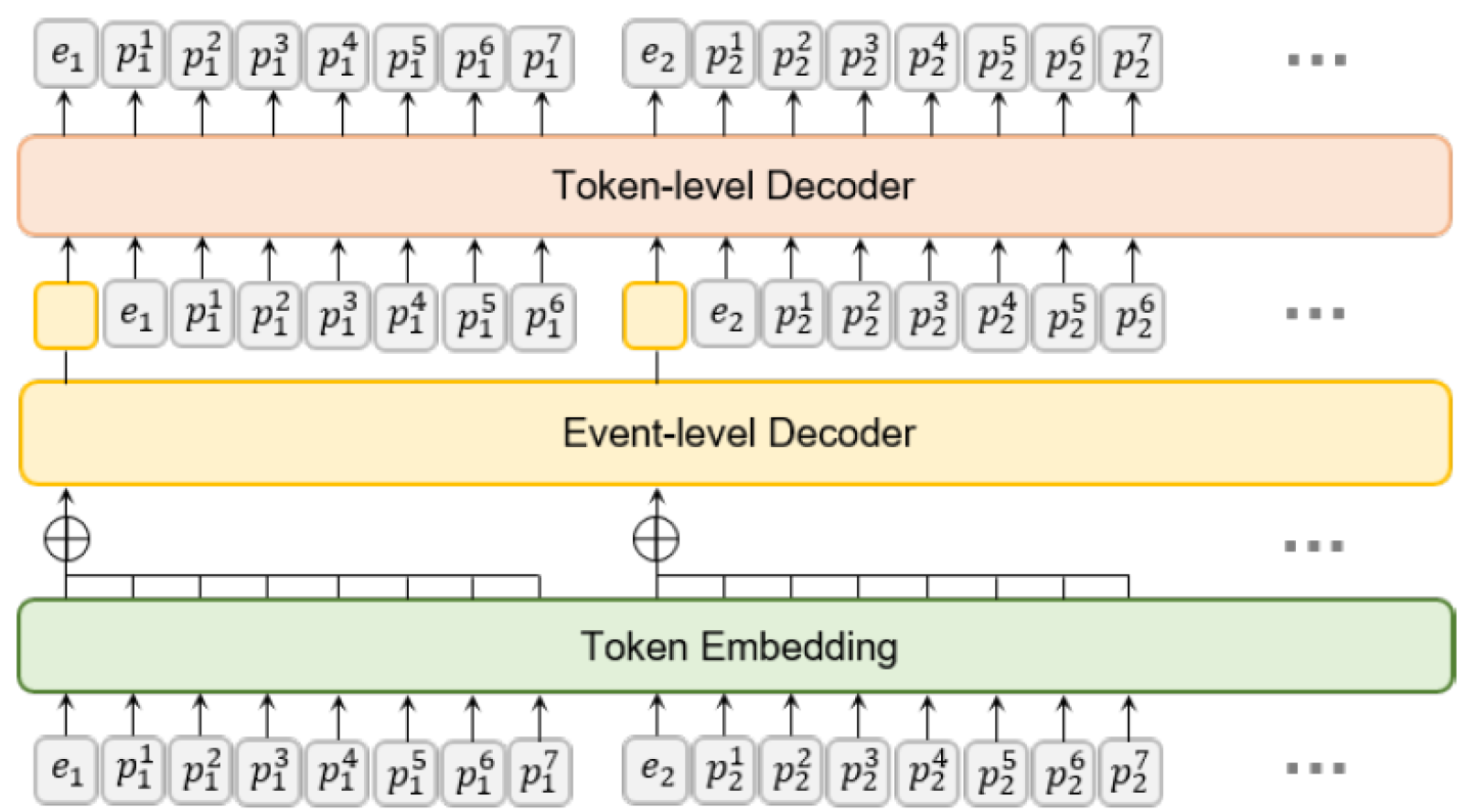
Each MIDI event (note, program change, control change, etc.) is represented as a sequence of tokens:
\(s_i = {e_i, p_i^1, p_i^2, ..., p_i^n}\)(1)Where \(e_i\) is the event type and \(p_i^j\) are the event parameters (up to 8 tokens per event).
Comprehensive Musical Representation
This tokenization scheme encodes a much richer set of musical information:
- Precise Timing: Using both beat-level (Time 1) and sub-beat (Time 2) tokens allows for accurate rhythmic alignment.
- Musical Structure: Encodes time signatures, key signatures, and tempo changes.
- Expression Control: Includes velocity, program changes, and controller information.
Crucially, the two-level architecture allows the event transformer to model long-range dependencies between musical events, while the token transformer handles the specifics of how each event is realized.
Training Complexity
The increased complexity introduces significant trade-offs:
-
Resource Requirements: Training requires substantially more computational resources, necessitating a more powerful GPU (A100) for efficient training.
-
Data Demands: The model requires much more training data to prevent overfitting. The 570 MIDI files sufficient for the base transformer proved inadequate here, requiring expansion to the POP909 dataset (~3,000 high-quality MIDI sequences after augmentation).
-
Training Duration: Convergence takes significantly longer, with the model continuing to improve even after 5,000+ training steps.
-
Hyperparameter Sensitivity: Finding optimal configurations proved more challenging, requiring careful tuning of learning rates, model dimensions, and training schedules.
This increased complexity is justified by the superior musical results, particularly the rhythmic precision that aligns generated notes correctly to the beat grid—a critical requirement for practical use in music production.
Architectural Parameters
The dual transformer uses significantly larger model dimensions:
- Event Transformer: 1024-dimensional embeddings, 8 attention heads, 10 layers
- Token Transformer: 1024-dimensional embeddings, 4 attention heads, 3 layers
This contrasts with the Base Transformer's more modest 512-dimensional embeddings and 6-layer architecture, further highlighting the computational trade-offs between approaches.
What I Discovered (Results)
After implementing and training both models, the differences in their performance proved both significant and revealing about the relationship between architectural decisions and musical output quality.
Training Performance
The Base Transformer demonstrated remarkable training efficiency with the smaller lo-fi dataset. The validation loss consistently decreased throughout training without signs of overfitting, reaching convergence after approximately 3,000 steps.
When trained on the larger POP909 dataset, the Base Transformer hit a performance ceiling at a loss of around 1.5, indicating its tokenization approach limited its ability to extract deeper patterns from more diverse data.
Training Metrics: Base Transformer
- Convergence: ~3,000 steps
- Training hardware: GTX 3070Ti (consumer-grade)
- Training time: Several hours
The Dual Event Transformer presented more significant challenges during training. Finding optimal hyperparameters required extensive experimentation, with the loss function often plateauing around 2.0 before slowly decreasing further. Even after 5,000 training steps, the loss continued to improve at a gradual rate, suggesting the model's capacity to represent complex musical relationships given sufficient training time.
Training Metrics: Dual Event Transformer
- Convergence: 6,000+ steps (continuing improvement)
- Training hardware: A100 GPU (professional-grade)
- Training time: Multiple days
This difference in training behavior reflects the architectural complexity gap between the models - the hierarchical organization of the Dual Transformer demanded more data and compute resources but ultimately learned more sophisticated representations.
Musical Assessment
The most significant differences emerged when examining the actual musical output produced by each model.
Melodic Coherence
Both models demonstrated the ability to generate tonally coherent melodies, maintaining consistent key centers and creating recognizable musical phrases. The Base Transformer quickly adapted to the lo-fi style, producing calming, repetitive melodic sequences characteristic of the genre.
Base Transformer Sample:
Note the consistent melodic patterns but subtle timing inconsistencies.
The Dual Transformer produced similarly coherent melodies, but with more sophisticated development and variation. Its hierarchical architecture enabled it to maintain thematic consistency while introducing musically appropriate deviations.
Dual Transformer Sample:
This sample demonstrates both coherent melody and precise rhythmic alignment.
Rhythmic Precision
The most pronounced difference between the models was in rhythmic handling:
The Base Transformer, despite its melodic strengths, consistently produced output with timing inconsistencies. Notes would frequently fall slightly off-beat in ways that would be immediately noticeable to musicians and problematic in production environments. This limitation stems directly from its simplified tokenization approach, which lacks explicit encoding of beat-level information.
The Dual Transformer, in contrast, demonstrated superior rhythmic precision. Notes consistently aligned with the musical grid, producing sequences that could be directly imported into a DAW without timing corrections. This improvement is attributable to two factors:
- The sophisticated MIDI tokenization scheme that explicitly represents timing relationships
- The hierarchical architecture that separately models event-level and token-level details
Base Transformer MIDI Visualization
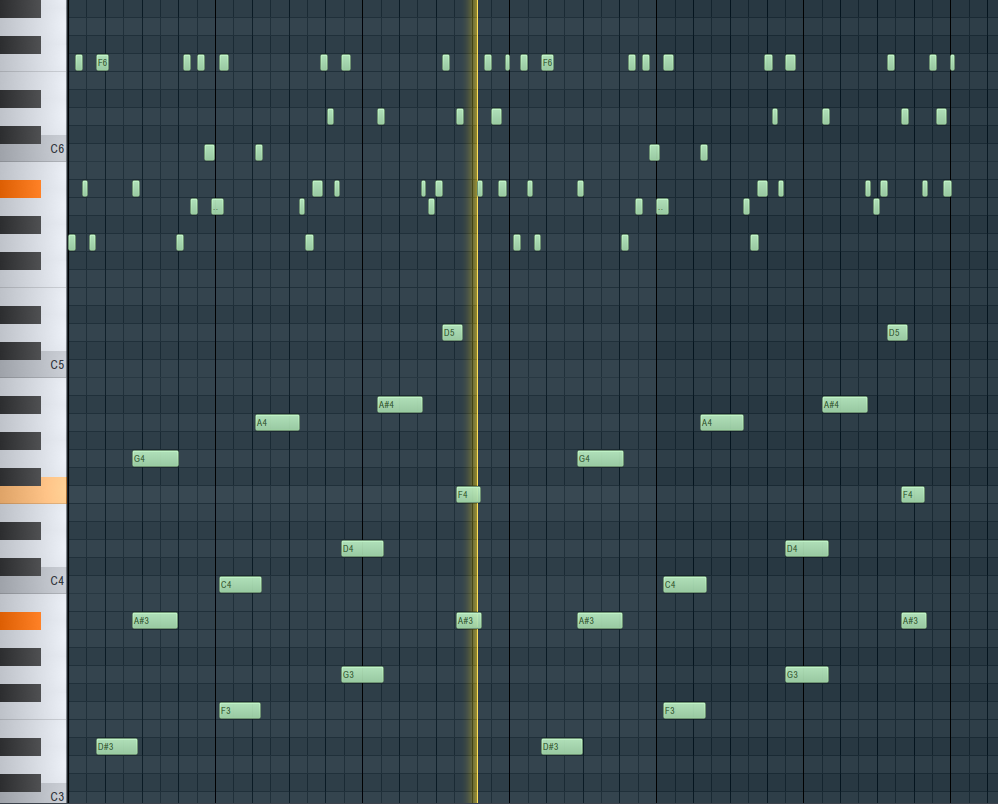
Dual Transformer MIDI Visualization

Note how notes align with the vertical grid lines (beat boundaries) in the Dual Transformer output but frequently miss alignment in the Base Transformer output.
Practical Usability
The technical differences between the models translate directly to their practical utility in music production:
The Base Transformer generates content that would require significant manual timing corrections before use in a professional context. While appropriate for rapid experimentation or idea generation, it falls short for production-ready output.
The Dual Transformer produces sequences that could be imported directly into a DAW and used with minimal adjustment. Its beat-aligned output integrates seamlessly with existing production workflows, substantially increasing its practical value despite the higher computational cost.
Conclusion: Architecture Matters
This exploration of different transformer architectures for MIDI generation reveals a significant trade-off between model complexity and musical quality, particularly regarding rhythmic precision.
The simpler Base Transformer demonstrates that even with minimal architectural complexity, coherent melodic generation is achievable. This approach offers advantages in training speed, computational efficiency, and data requirements, making it suitable for rapid prototyping or educational contexts where perfect rhythmic alignment isn't critical.
The more complex Dual Event Transformer, while demanding substantially more computational resources and training data, produces musically superior output with proper rhythmic alignment. This improvement in quality directly translates to practical utility in production environments, where integration with existing DAW workflows is essential.
Key Takeaways
-
Tokenization strategy significantly impacts model capabilities, particularly regarding rhythmic precision and musical structure.
-
Hierarchical architectures better capture music's inherent multi-level organization but require more extensive training and data.
-
Training requirements scale non-linearly with model complexity - the Dual Transformer required approximately 6,000 training steps versus 3,000 for the Base Transformer, along with substantially more training data.
-
Practical usability in production environments depends critically on rhythmic precision, which simple tokenization approaches struggle to achieve.